Data migration is one of the important and interesting tasks in Parcel Perform. It helps us to sync data between DBs, migrate obsolete data to a newer format, and change the data structure. For most migration tasks we follow a series of steps from preparation to execution and monitoring, usually:
- Writing queries to pick needed data;
- Preparing a script to do the data migration;
- Setting up resources to execute;
- Executing and keeping monitoring;
With the huge amount of data, splitting the migration into smaller parts, and running them in parallel to speed up the whole process is always recommended. However, we actually have no way but to run it on a single machine. That takes a lot of human effort to follow up its process, execute the next batch and repeat until all parts are completed. But there could be some unexpected troubles during execution which crash the migration, and we may need to restart from the beginning since the preparation might not be good enough to retry from where it got into trouble. For instance, we have to migrate our database after Vietnamese mobile network operators campaigned to change phone numbers from 11-digit to 10-digit in 2018. The first strategy of the migration is running a linear sequence top to bottom in a single thread, additionally, we do not really know where the migration has reached unless we store the id of the last record right before failure or getting a crash. That means there is no reliable way to retry unless the migration keeps track of its process. Moreover, running in a single thread definitely slows down the process drastically.
Therefore, with the flexibility and reliability in distributing tasks, we have counted on Celery to be an excellent distributor to handle all things about the migration.
What is Celery?
Celery is the one who helps us to build a space to execute tasks. I call it “a space” because every work in Celery systematically communicates via messages between clients and workers by a broker. In general, clients will request one or many tasks at the same time, meanwhile, the broker will take over these requests and distribute them to workers. In the whole process, Celery provides clients a way to initialize a task and gives Workers several steps to process that task; so that whenever a task is called, the broker receives a message including a definition of the task, arguments, and other necessary parameters, then, distributes it to a corresponding worker to handle. The result of execution can be recorded into a backend part.
Regarding migration, Celery could be the best tool to help manage migration tasks efficiently. To avoid the need to manually follow the process, all we need to do is prepare an application to separate migration into tasks and have Celery distribute tasks to Workers.
Migration tool

Application
In Django management command, by taking advantage of the convenience of Celery, we implement an application to undertake the request from the client to make a plan, including:
- migration data: records to migrate, which will be pulled from the database by a given query;
- migration script: script which is in hand on how to process a record;
- batch size: how many records will be processed in a task;
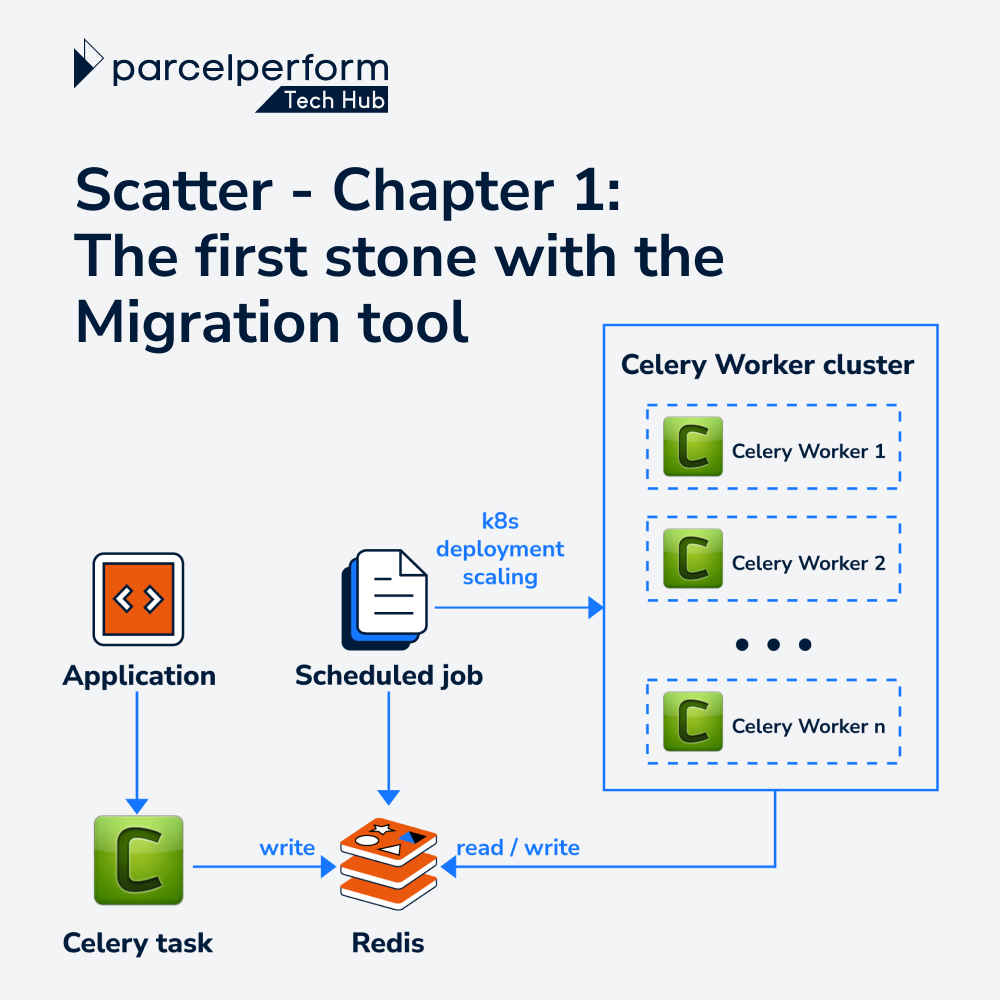
Once receiving a request, the application will collect data, chunk them into smaller batches, and prepare all needed parameters. These batches will be pushed into S3 storage as resources for the migration’s next steps. Finally, the message which includes parameters along with the S3 key of the resource packed will be registered as a task to the Celery broker. Right after receiving a distributed message from queue, Worker will unpack the message and execute the migration one by one.
Broker
At the moment, Celery supports many types of MQ as broker; two of them are RabitMQ and Redis, known as stable types with supporting full functionality of remote controlling and monitoring. There are several different things between them: Redis has super-fast key-value storing so it is very efficient for fetching the results of a task call, meanwhile, RabitMQ is robust in handling more significant messages better than Redis. However, based on the use case of migration, we decide to use Redis as basically it is already available in our system infrastructure, and ready to have a standalone one rather than setting up and introducing a new RabitMQ. Previous articles mentioned that we favor using Redis Cluster for its scalability and cost-saving in improving performance. Unfortunately, Celery does not support Redis Cluster itself, we would have to do extra customization to make Celery compatible with it. That is really unnecessary since using Redis as a broker is relatively light in terms of both storage and read/write throughput. Thus, a standalone Redis was chosen.
Workers
Finally, the endpoint of the migration process is Celery Workers. A worker will handle one or some of the tasks concurrently in a defined queue by executing given scripts to apply the change to data. During processing tasks, the retry mechanism always being ready to deal with configured allowance exceptions to cover unexpected failures. At the last of the process, the Worker is the one who will deliver the result details by the planned fallbacks before taking another one. That sequential operation creates the rhythmical work on each Worker and the whole migration chain.
Auto-scaling Worker cluster
Resource management is crucial for the migration tool as we do not really use it that often. Thus having a bunch of machines online all the time is unnecessary and wasteful. On the other hand, in many situations, we may also need a ton of instances to take on a migration request. Auto-scaling on the Worker cluster allows them to turn on and shut down Workers deliberately according to the number of tasks in the queue. There were several approaches to implementing auto-scaling clusters, and K8s is the chosen one due to our operation experience with it compared with AWS Auto Scaling Group (ASG) or AWS EC2 API. In addition, scaling up/down by specifying the resource up to pod level on K8s makes it easier, by request on single command lines or APIs. As such, the migration tool has a cron job working scheduled to check and count tasks on Redis, calculate the number of machines needed, and call K8s API to start new Workers or shut down some to save cost.
Conclusion
With the flexibility and reliability of Celery, the migration tool operates pretty rhythmically to be able to take over a large number of migration tasks without manual and complex control but ensure saving cost with the auto-scaling feature. Splitting up into tasks for running parallelism can speed up the whole migration effectively. Several quick comparisons on syncing requests for one-day data with ~1.5M records, it takes around 2-3 days in a single machine to finish the task, meanwhile, it is less than 18 hours to run in parallel on the migration tool with 10 Workers. Besides, to keep track of a migration process for the retry mechanism, each worker will cache the latest id of record by a task, and always be ready to recover the execution. Thus, regardless of interruption or worker termination, the task will be resumed once it is back.
Extending the scope of the migration tool, Celery should be a perfect fit for simplifying asynchronous processing in implementation as well as setting up. Therefore, from the first stone with the migration tool, we are going to plan for Scatter development as an external module for any distribution use case. The next chapter will discuss what Scatter is, is not, will, and will not be.


