
From the beginning, we have been using Redshift as our data warehouse, serving our internal and customer-facing data analytics workloads. It has been serving us “well” in most of the cases. There are certain drawbacks:
- ETL pipelines: data are actually transformed, joined, denormalized via application-based CDC before ingested by Redshift. As the transformation are handled at source, the CDC pipelines are simple and straight forward but there are two issues:
- ETL pipelines create a coupling between data engineer team and data analysis team, who always need to wait for new pipelines developed whenever there are new data introduced to Redshift
- Application-based-cdc creates loads (huge one!) on our main database and core services. Hence, it’s a challenge everytime our system need to be scaled-up, preparing for up-coming traffic, Black Friday and Cyber Monday sales as an example.
- There are tables that are used for both our internal and customer-facing features, making it extremely difficult for optimizing performances or migrating these tables.
As a data driven company, there are more and more data ingesting by us, a more modern approach is indeed a must to help us scaling faster and in a more sustainable way.
Our main goals are:
- Sunsetting application-based CDC and adoptting write-ahead-log (WAL) CDC. Which doesn’t cause extra workload on our infra.
- Moving toward ELT pipelines, decoupling our DE and DA teams workloads. This is a big plus as DA are totally free to explore and transform data as their needs.
- Increasing performance for our data analytics customer-facing features, which are strongly dependent on Redshift at the moment
We are trying out available options. The first one is a data-lake architecture, in which:
- Data are captured by Debezium WAL CDC, then consumed by Apache Flink pipelines
- Data are store in S3 with Apache Iceberg as our table format.
- Data exploration via AWS Athena as query engine
- Reports and other workloads via AWS AWS Glue as compute engine
- We also use schema registry to support schema evolution

Let’s explore our journey via this blog
Before that, Some insights of our data model.
Mutable changing facts
In our data models, parcel, events of parcels and the shipment of those parcels are considered 3 separate facts. It is a one-to-many relationship between a shipment and an parcel, between a shipment and an event. When a fact or dimension changes, it reflects the changes on the other facts hence the facts are intentionally let mutable.
Mutable facts are rarely used, but it is a valid choice for our case. There are challenges for ingesting these facts from an OLAP standpoint, especially as the facts are updated so frequently and randomly distributed when partitioned by the time the facts are first introduced to our system
We don’t have historical data, only latest data
As our facts are mutable, we still update these facts even if they were imported to our system years ago, mostly to correct them. This is the daily use case as the metadata coupled with these facts may not be interpreted correctly by our algorithm at the time, so they are updated again once our master data team perform their evaluation.
The consequences that we don’t have historical data, only latest data which are more and more accurate overtime.
Current available table formats
It is an interesting time for DE to choose a table format as there are many of them available, considering HIVE for a long time, was the only option.
For this blog, we don’t go over comparing them again,
A good piece from Dremio could be found here
We ended up choosing Apache Iceberg for our first POC due to below reasons:
- Apache Iceberg upsert support could be a good fit for the mutable changing facts
- Schema evolution and especially partition evolution supports could be potentially helpful for us in the long run
- On paper, performance seems great when comparing to other formats
- AWS Athena already supports Apache Iceberg table format
POC journey
What we’ve learned
The POC setup is straight forward:
- WAL CDC events are consumed by Apache Flink pipelines, then sink to S3 under Iceberg table format.
- Apache Iceberg tables are configured in upsert mode to store the latest data
- The Apache Iceberg catalog implementation is AWS Glue catalog
- There’s a daily AWS Glue maintenance job, to expire old snapshots and compact small files into bigger one.
The setup went smoothly as the Apache Iceberg in both AWS Glue and Flink are well implemented and documented. However, soon we’ve learned a few but big caveats that prevent us to use this table format after all …
It is worth mentioning that we used Apache Iceberg version 0.14.1 for the POC.
Too many small files are the source of all the problems
A naive thought, our data in the lake are partitioned based on the imported_date, which is the time when events are introduced into our system. We chose this field as our main partition for two reasons:
- The imported_date remains constant throughout the life cycle of a record, and when combined with the primary key, it helps Apache Iceberg to always select the correct partition and files for appending or updating corresponding records.
- Our read queries always filter based on a range of imported dates, allowing us to easily perform predicate pushdown on files per imported_date to optimize our read queries.
However, our data is frequently updated on arbitrary imported_dates, resulting in many small files in most partitions on a daily basis.
We didn’t initially recognize this problem when the POC was running in our staging environment, as the data size was limited to hundreds of megabytes and did not accurately reflect the behavior of our core application’s database updates.
At the time, the Apache Iceberg table format seemed promising, as it kept latency low (at 5 minutes) and compaction on AWS GLUE was quick (under 5 minutes). However, once we ran the POC in the production environment with real data, all the problems emerged.
Flink checkpoint vs Iceberg sink distribution mode vs file size
The Iceberg sink component commits a snapshot when a checkpoint occurs, therefore, the more frequent the checkpoint, the more files there will be.
With the hash distribution mode, it is ensured that there is only one writer for each partition at a time. Example:
| Checkpoint interval | Files per Partition per Day (Hash Distribution Mode) |
|---|---|
| 5 minutes | 288 files/partition/day |
| 30 minutes | 48 files/partition/day |
| 1 hours | 24 files/partition/day |
On the other hand, without the hash distribution, the number of writers for each partition will depend on the parallelism of the Flink pipeline.
For example, with parallelism equal to 4:
| Checkpoint interval | Files per Partition per Day (No Hash Distribution) |
|---|---|
| 5 minutes | 1152 files/partition/day |
| 30 minutes | 144 files/partition/day |
| 1 hours | 72 files/partition/day |
Given that on a daily basis, our data is distributed across at least 700 partitions, this results in a large number of small files, leading to poor query performance as the files are not in optimal sizes.
To address this issue, compaction of the Iceberg table is compulsory.
What we mean by small files and too many of them
S3 recommended file size are from 128MB TO 1GB, our file sizes are from few KBs to hundred MB. Below is a table of file size distribution on one of our table.
Our mutable fact Iceberg table, when data are first loaded
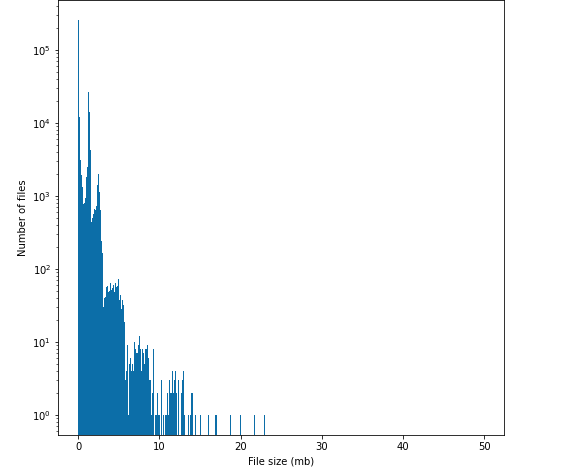
Our normal case, 8 hours after the nearest compaction
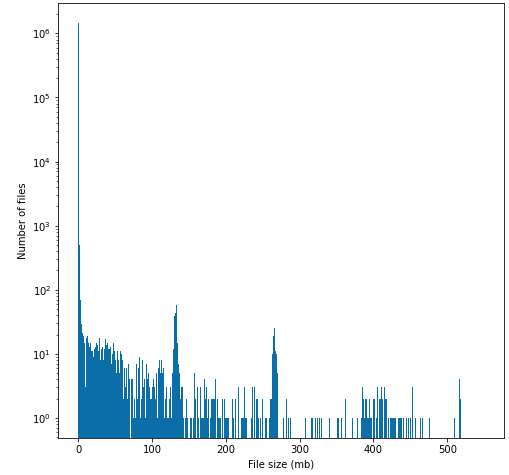
There are compacted files introduced to the graph ( > 512MB files), but there are still too many small files of the current CDC pipeline after the compaction.
Last but not least, the file distribution of the same table but in Hive format
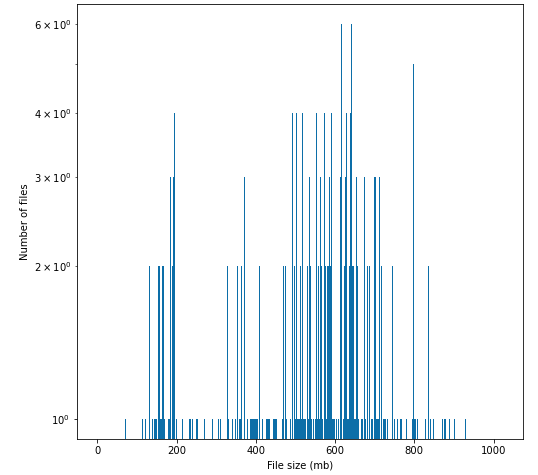
From the above graphs, we have below summary:
Regarding the number of files:
- Table with Hive format has 4 to 5 magnitude fewer files than Iceberg tables for our case
- The Iceberg CDC table has one magnitude more files than when it is initially loaded
Regarding file sizes:
- File size distribution of Hive table format are in optimal range recommended for AWS S3 while Iceberg tables are clearly out of optimal range
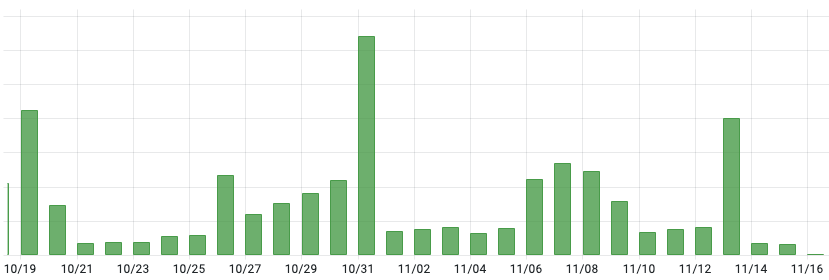
We suffered from this issue badly:
- The S3 cost is tremendous!
- The query performance is bad (which we described further in the next section)
Below is the S3 cost of the data-lake bucket storage alone, partitioned by day. The storage cost is relative low but spikes to high number when there are queries or compactions. This is due to the increase in the number of read requests, millions of them …
Query performance
We conducted a performance test on some of our daily queries using Redshift, Athena, Glue, and Trino. As a result:
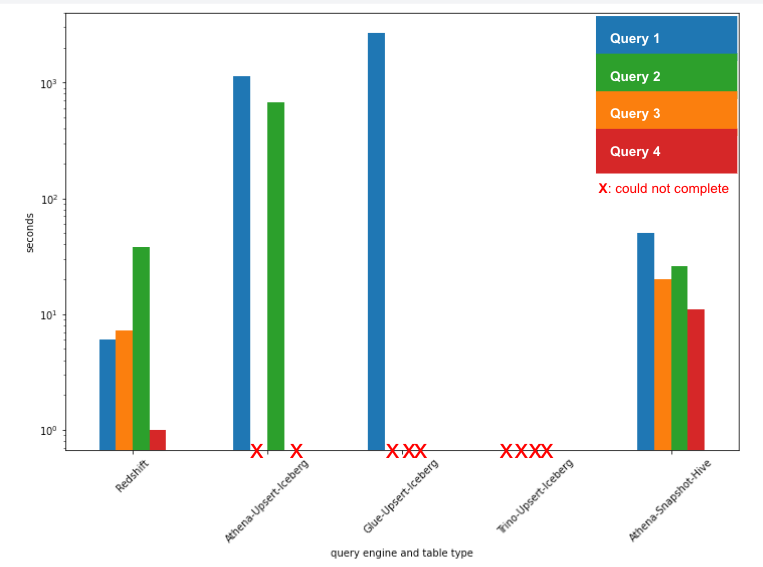
- Redshift, with its joined and denormalized tables, was the fastest, with results returned within seconds.
- Athena with Hive snapshot tables was one magnitude slower, taking approximately 100 seconds to complete the queries.
- Most of our queries using Athena with upsert Iceberg tables either timed out or returned internal errors, even when run on freshly compacted tables.
- In theory, Glue/Trino could perform the queries, but they were 1000 times slower than Redshift, taking anywhere from a few hours to half a day to complete.
Compaction is tricky!
On paper, the compaction seems to be straight forward as Apache Iceberg community teams already implement the compaction for both Spark and Flink. Though tuning the compaction to run properly is tricky:
-
Apache Iceberg use optimistic locking when committing metadata. This means if there are multiple writers concurrently updating the Apache Iceberg table, they will race with each other to have the right for commiting the metadata file. This is an issue when compacting job takes longer than the checkpoint interval of CDC pipeline. Sometime the compaction is completed but the commit fails due to the racing condition. It is really expensive when we fall into this scenario.
- we can enable partial commit for the compacting job, this is a way to reduce the chance of conflict but not competely resolve it. In our case, the race eventually happens and the compacting job skipped few times. This reflects on longer and longer compacting time in the next runs
- As a result, we need to find an equilibrium for CDC pipeline checkpoint interval and our compaction interval. We found that it is 30 minutes for Flink checkpoint and once a day for compaction
-
MAX_CONCURRENT_FILE_GROUP_REWRITES_DEFAULT is 1
- The rewrite-data-files procedure described here doesn’t mention this flag directly. We only found out that we are not utilizing all the spark nodes until we started loading big table to S3 under Iceberg format, then compaction took almost 1 day to complete …
- When we changed the concurrent file group rewrite setting to 100, the actual compact job took under 2 hours with a 20 AWS Glue DPU.
Issues with Flink and AWS Glue
- Hidden partition not supported in Apache Flink
- Flink parquet reader does not support complex type Apache Flink
- Merge into statement not runnable (AWS Glue)
Conclusion
After of two months conducting the POC, we are now clear that Apache Iceberg is not suitable for us. We’re switching back to Hive with the tradeoff of data freshness. In return, a much lower operation/maintenance cost and under-30-minutes-query-time guaranteed for all of our use cases.
The initial goal was that we could serve our DA team using Apache Iceberg table, in upsert mode, with sub hour data freshness. It is not the case though.
We are now providing our DA team a T-1 day data freshness for data exploration and daily related report generation. While more SLA-demanding, sub-hour, real time reports will be treated with custom Flink pipelines of their own.


